Sql Server Index 평균 조각화 인덱스를 다시 작성 REBUILD 하거나 다시 구성 REORGANIZE 하기
Sql Server Index 인덱스를 다시 작성 REBUILD 하거나 다시 구성 REORGANIZE 하기
데이터베이스에서 평균 조각화가 10%를 넘는 모든 파티션을 자동으로 다시 구성(REORGANIZE)하거나 다시 작성(REBUILD)합니다. 이 쿼리를 실행하려면 VIEW DATABASE STATE 권한이 필요합니다.
이 예에서는 데이터베이스 이름을 지정하지 않고 DB_ID를 첫 번째 매개 변수로 지정합니다. 현재 데이터베이스의 호환성 수준이 80 이하이면 오류가 발생합니다. 오류를 해결하려면 DB_ID()를 올바른 데이터베이스 이름으로 대체합니다. 데이터베이스 호환성 수준에 대한 자세한 내용은 ALTER DATABASE 호환성 수준(Transact-SQL)을 참조하세요.
ALTER DATABASE compatibility level (Transact-SQL) - SQL Server
ALTER DATABASE compatibility level (Transact-SQL)
docs.microsoft.com
조각화가 10%를 넘는 인덱스를 조회하여, REORGANIZE 또는 REBUILD 해서 동적으로 쿼리문을 만들어 exec 바로 실행합니다. 온라인을 사용하면 운영 중 lock 발생이 없어서 안정성이 존재하지만, standard 버전에서는 제공해 주지 않으니 참고하시기 바랍니다.
-- Ensure a USE <databasename> statement has been executed first.
SET NOCOUNT ON;
DECLARE @objectid int;
DECLARE @indexid int;
DECLARE @partitioncount bigint;
DECLARE @schemaname nvarchar(130);
DECLARE @objectname nvarchar(130);
DECLARE @indexname nvarchar(130);
DECLARE @partitionnum bigint;
DECLARE @partitions bigint;
DECLARE @frag float;
DECLARE @command nvarchar(4000);
-- Conditionally select tables and indexes from the sys.dm_db_index_physical_stats function
-- and convert object and index IDs to names.
SELECT
object_id AS objectid,
index_id AS indexid,
partition_number AS partitionnum,
avg_fragmentation_in_percent AS frag
INTO #work_to_do
-- DB_ID(특정 database명) 사용가능
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL , NULL, 'LIMITED')
WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0;
-- Declare the cursor for the list of partitions to be processed.
DECLARE partitions CURSOR FOR SELECT * FROM #work_to_do;
-- Open the cursor.
OPEN partitions;
-- Loop through the partitions.
WHILE (1=1)
BEGIN;
FETCH NEXT
FROM partitions
INTO @objectid, @indexid, @partitionnum, @frag;
IF @@FETCH_STATUS < 0 BREAK;
SELECT @objectname = QUOTENAME(o.name), @schemaname = QUOTENAME(s.name)
FROM sys.objects AS o
JOIN sys.schemas as s ON s.schema_id = o.schema_id
WHERE o.object_id = @objectid;
SELECT @indexname = QUOTENAME(name)
FROM sys.indexes
WHERE object_id = @objectid AND index_id = @indexid;
SELECT @partitioncount = count (*)
FROM sys.partitions
WHERE object_id = @objectid AND index_id = @indexid;
-- 30 is an arbitrary decision point at which to switch between reorganizing and rebuilding.
IF @frag < 30.0
SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REORGANIZE';
IF @frag >= 30.0
SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD';
IF @partitioncount > 1
SET @command = @command + N' PARTITION=' + CAST(@partitionnum AS nvarchar(10));
EXEC (@command);
PRINT N'Executed: ' + @command;
END;
-- Close and deallocate the cursor.
CLOSE partitions;
DEALLOCATE partitions;
-- Drop the temporary table.
DROP TABLE #work_to_do;
GO<docs.microsoft.com 에서 발췌한 인덱스를 다시 작성하거나 다시 구성하는 쿼리>
sys.dm_db_index_physical_stats 에서 반환된 결과 집합은 다음 열을 포함합니다.
| avg_fragmentation_in_percent | 논리적 조각화(인덱스에서 순서가 잘못된 페이지) |
| avg_page_space_used_in_percent | 평균 페이지 밀도 |
인덱스를 다시 작성하면 이 인덱스가 삭제된 다음 다시 생성됩니다. 인덱스 유형과 데이터베이스 엔진 버전에 따라 온라인이나 오프라인에서 다시 작성 작업을 수행할 수 있습니다. 오프라인 인덱스 다시 작성은 온라인 다시 작성보다 일반적으로 시간이 덜 걸리지만 다시 작성 작업 중에 개체 수준 잠금이 유지되기 때문에 테이블이나 뷰에 쿼리가 액세스할 수 없도록 차단됩니다.
온라인 인덱스 다시 작성은 다시 작성을 완료하기 위해 잠깐 동안 잠금을 유지해야 하는 작업이 끝날 때까지 개체 수준 잠금이 필요하지 않습니다. 데이터베이스 엔진 버전에 따라 온라인 인덱스 다시 작성을 다시 시작 가능한 작업으로 시작할 수 있습니다. 다시 시작 가능한 인덱스 다시 작성은 작업을 일시 중지하고, 해당 지점까지의 진행 상태를 유지할 수 있습니다. 다시 시작 가능한 다시 작성 작업은 일시 중지 또는 중단했다가 다시 시작하거나, 다시 작성을 완료할 필요가 없으면 중단할 수 있습니다.
Transact-SQL 구문에 대한 자세한 내용은 ALTER INDEX REBUILD를 참조하세요. 온라인 인덱스 다시 작성에 대한 자세한 내용은 온라인으로 인덱스 작업 수행을 참조하세요.
다음 예제에서는 AdventureWorks 데이터베이스의 기존 온라인 인덱스를 다시 작성합니다.
온라인으로 인덱스를 만들거나, 다시 작성하거나, 삭제하려면 REBUILD WITH (ONLINE = ON); 를 사용합니다.
ALTER INDEX AK_Employee_NationalIDNumber
ON HumanResources.Employee
REBUILD WITH (ONLINE = ON);
인덱스의 조각화 줄이기
인덱스의 조각화가 쿼리 성능에 영향을 미치는 경우 다음 세 방법 중 하나를 사용하여 조각화를 줄일 수 있습니다.
- 클러스터형 인덱스를 삭제한 다음 다시 만듭니다.
클러스터형 인덱스를 다시 만들면 데이터가 재구성되어 완전한 데이터 페이지가 만들어집니다. 사용률 수준은 CREATE INDEX의 FILLFACTOR 옵션으로 구성할 수 있습니다. 이 방법의 단점은 삭제하거나 다시 만드는 동안 인덱스가 오프라인 상태라는 것과 작업의 원자성에 있습니다. 인덱스 생성이 중단되면 그 인덱스는 다시 생성되지 않습니다. 자세한 내용은 CREATE INDEX(Transact-SQL)를 참조하세요. - DBCC INDEXDEFRAG 대신 ALTER INDEX REORGANIZE 를 사용하여 인덱스의 리프 수준 페이지를 논리적 순서로 다시 정렬합니다. 이 작업은 온라인 작업이므로 문이 실행 중일 때 인덱스를 사용할 수 있습니다. 또한 작업이 중단되더라도 이미 완료된 작업은 손실되지 않습니다. 이 방법의 단점은 데이터를 다시 구성하는 작업이 인덱스를 다시 작성하는 작업만큼 효과적이지 않다는 것과 통계가 업데이트되지 않는다는 것입니다.
- DBCC DBREINDEX 대신 ALTER INDEX REBUILD를 사용하여 인덱스를 온라인이나 오프라인 상태로 다시 작성합니다. 자세한 내용은 ALTER INDEX(Transact-SQL)를 참조하세요.
인덱스를 다시 구성하거나 작성하는 이유가 전적으로 조각화 때문만은 아닙니다. 조각화는 주로 인덱스 검색 중 페이지 미리 읽기 성능을 저하시킵니다. 이로 인해 응답 시간이 느려집니다. 조각화된 테이블이나 인덱스에 대한 쿼리 작업은 기본적으로 단일 조회이기 때문에 검색과 관련이 없는 경우에는 조각화를 제거하더라도 효과를 기대하기 어려울 수 있습니다.
REORGANIZE 와 REBUILD 차이
인덱스 REORGANIZE 작업에는 page_id의 변화 없이 순서만 정렬되어 다시 구성되었는데,
인덱스 REBUILD 작업이 완료된 이후에는 새로운 page_id의 페이지가 생성되어 있는 것을 확인할 수 있습니다. 이렇게 인덱스 REBUILD 는 인덱스를 완전히 삭제하고 새로 구성하게 됩니다.
그래서 인덱스 REBUILD 에 소요되는 시간과 리소스가 인덱스 REORGANIZE 에 비해서 더 크며, 일정 수준 이상의 조각화(일반적으로 약 30% 이상)가 발생한 경우에는 인덱스 REBUILD 를 진행해야 인덱스의 조각화를 해결할 수 있습니다. (다니엘의 라이브러리 블로그 부분 발췌)
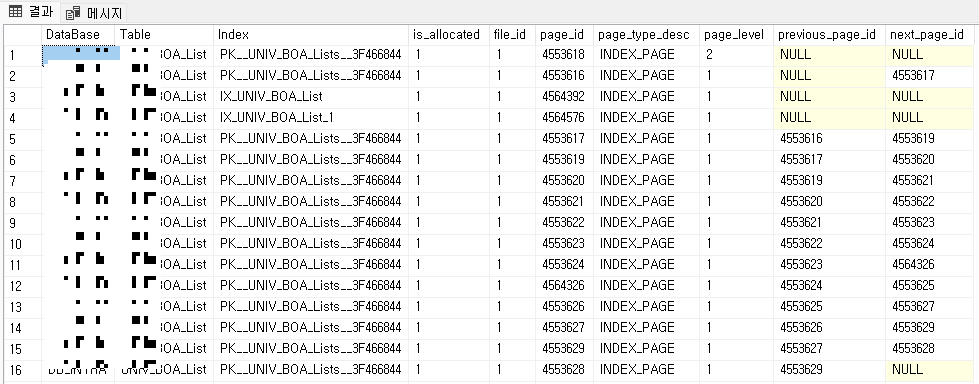
테이블 Customers와 연결된 모든 페이지 가져오기
테이블과 연결된 모든 Page 를 가져오려면 DMF sys.dm_db_database_page_allocations 의 @DatabaseId, @TableId 및 @Mode 매개 변수 값만 전달하면 됩니다. 이 정보를 얻기 위해 아래와 같은 쿼리를 작성할 수 있습니다.
SELECT DB_NAME(PA.database_id) [DataBase],
OBJECT_NAME(PA.object_id) [Table], SI.Name [Index],
is_allocated, allocated_page_file_id [file_id],
allocated_page_page_id [page_id], page_type_desc,
page_level, previous_page_page_id [previous_page_id],
next_page_page_id [next_page_id]
FROM sys.dm_db_database_page_allocations
(DB_ID('database 명'),
OBJECT_ID('테이블명'),NULL, NULL, 'DETAILED') PA
LEFT OUTER JOIN sys.indexes SI
ON SI.object_id = PA.object_id
AND SI.index_id = PA.index_id
ORDER BY page_level DESC, is_allocated DESC,
previous_page_page_id
참고사이트
https://datalibrary.tistory.com/128
[SQL Server] 인덱스 재구성 vs 인덱스 리빌드 차이 한 눈에 이해하기
안녕하세요. 이번 시간에는 SQL Server의 인덱스 재구성(Reorganize)과 리빌드(Rebuild)의 차이에 대해서 알아보도록 하겠습니다. 지난 포스팅에서 I/O의 단위가 되는 페이지에 새로운 데이터가 추가될
datalibrary.tistory.com
https://sqlhints.com/tag/how-to-get-all-the-pages-of-an-index/
How to Get all the Pages of an Index? – SqlHints.com
I was writing an article on when and why we have to use included columns and wanted to explain it by showing how key column and included column values are stored in the Index Pages. That time, I got realized that first I need to explain how we can look int
sqlhints.com
sys.dm_db_index_physical_stats(Transact-SQL) - SQL Server
sys.dm_db_index_physical_stats(Transact-SQL)
docs.microsoft.com
'데이터베이스 > MS-SQL 😃' 카테고리의 다른 글
| .NET 과 SQL Server 의 Data Type Mapping (데이터 형식 매핑) (2) | 2022.11.28 |
|---|---|
| mssql : bytes 숫자를 mb 또는 kb 로 변환해 보기 (2) | 2022.10.21 |
| MSSQL : LIKE 구문 사용시 와일드카드 문자 Wildcard Characters 대처하는 방안 [번역] (2) | 2022.04.14 |
| MSSQL : 계층형 TREE 트리 구조의 TABLE 테이블 구현하기 (7) | 2021.08.04 |
| mssql : database 들의 connections 커넥션 의 개수 확인하기 (0) | 2021.07.13 |